I stumbled across this awesome article today: Revving Up Your Hibernate Engine.
Well worth the read if you are or are planning to use Hibernate in the near future.
To quote the summary of the article:
"This article covers most of the tuning skills you’ll find helpful for your Hibernate application tuning. It allocates more time to tuning topics that are very efficient but poorly documented, such as inheritance mapping, second level cache and enhanced sequence identifier generators.
It also mentions some database insights which are essential for tuning Hibernate.
Some examples also contain practical solutions to problems you may encounter."
Friday, December 31, 2010
Friday, December 24, 2010
Find all the classes in the same package
It's been a slow month for blogging, due to the release of a new World of Warcraft expansion, crazy year end software releases at work and the general retardation of the human collective consciousness that happens this time of year.
With all of that I did however have some fun writing the following bit of code. We have a "generic" getter and setter test utility used to ensure a couple extra %'s of code coverage with minimal effort. That utility did however requires that you call it for every class you want to test, being lazy I wanted to just give it a class from a specific package and have that check all the classes.
I initially thought there would have to be just a simple way to do it with the Java reflection API. Unfortunately I didn't find any, it seems a "Package" does not keep track of it's classes, so after a bit of digging on the net and feverish typing (ignoring the actual project I am currently working on for a little) here is what I came up with. The tip is actually the just methods from the java.lang.Class object: "getProtectionDomain().getCodeSource().getLocation().toURI()", giving you the base to work from and I found that somewhere on Stackoverflow.
There are 2 public methods: findAllClassesInSamePackage and findAllInstantiableClassesInSamePackage. (For my purposes of code coverage I just needed the instantiable classes.)
Usage:
PackageClassInformationFinder:
With all of that I did however have some fun writing the following bit of code. We have a "generic" getter and setter test utility used to ensure a couple extra %'s of code coverage with minimal effort. That utility did however requires that you call it for every class you want to test, being lazy I wanted to just give it a class from a specific package and have that check all the classes.
I initially thought there would have to be just a simple way to do it with the Java reflection API. Unfortunately I didn't find any, it seems a "Package" does not keep track of it's classes, so after a bit of digging on the net and feverish typing (ignoring the actual project I am currently working on for a little) here is what I came up with. The tip is actually the just methods from the java.lang.Class object: "getProtectionDomain().getCodeSource().getLocation().toURI()", giving you the base to work from and I found that somewhere on Stackoverflow.
There are 2 public methods: findAllClassesInSamePackage and findAllInstantiableClassesInSamePackage. (For my purposes of code coverage I just needed the instantiable classes.)
Usage:
PackageClassInformationFinder:
Sunday, December 5, 2010
Enabling enterprise log searching - Playing with Hadoop
Having a bunch of servers spewing out tons of logs is really a pain when trying to investigate an issue. A custom enterprise wide search would just be one of those awesome little things to have and literally save developers days of their lives not to mention their sanity. The "corporate architecture and management gestapo" will obviously be hard to convince, but the chance to write and setup my own "mini Google wannabe" MapReduce indexing is just too tempting. So this will be a personal little project for the next while. The final goal will be distributed log search, using Hadoop and Apache Solr. My environment this mostly consists of log files from:
Weblogic Application server, legacy CORBA components, Apache, Tibco and then a mixture of JCAPS / OpenESB / Glasshfish as well.
Setting Up Hadoop and Cygwin
First thing to get up and running will be Hadoop, our environment runs on windows and there in lies the first problem. To run Hadoop on Windows you are going to need Cygwin.
Download: Hadoop and Cygwin.
Install Cygwin, just make sure to include the Openssh package.
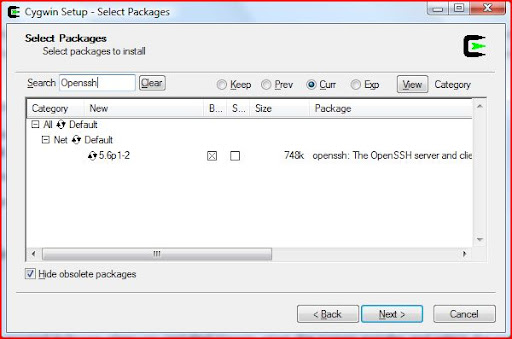
Once installed, using the Cygwin command prompt: ssh-host-config
This is to setup the ssh configuration, reply yes to everything except if it asks
"This script plans to use cyg_server, Do you want to use a different name?" Then answer no.
There seems to be a couple issues with regards to permissions between Windows (Vista in my case), Cygwin and sshd.
Note: Be sure to add your Cygwin "\bin" folder to your windows path (else it will come back and bite you when trying to run your first map reduce job)
and typical to Windows, a reboot is required to get it all working.
So once that is done you should be able to start the ssh server: cygrunsrv -S sshd
Check that you can ssh to the localhost without a passphrase: ssh localhost
If that requires passphrase, run the following:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Now back to the Hadoop configuration:
Assuming that Hadoop was downloaded and unzipped into a working folder, ensure that the JAVA_HOME is set. Edit the [working folder]/conf/hadoop-env.sh.
The go into [working folder]/conf, and add the following to core-site.xml:
To mapred-site.xml add:
Go to the hadoop folder: cd /cygdrive/[drive]/[working folder]
format the dfs: bin/hadoop namenode -format
Execute the following: bin/start-all.sh
You should then have the following URLs available:
http://localhost:50070/
http://localhost:50030/
A Hadoop application is made up of one or more jobs. A job
consists of a configuration file and one or more Java classes, these will interact with the data that exists on the Hadoop distributed file system (HDFS).
Now to get those pesky log files into the HDFS. I created a little HDFS Wrapper class to allow me to interact with the file system. I have defaulted to my values (in core-site.xml).
HDFS Wrapper:
I also found a quick way to start searching the log file uploaded, is the Grep example included with Hadoop, and included it my HDFS test case below. Simple Wrapper Test:
Weblogic Application server, legacy CORBA components, Apache, Tibco and then a mixture of JCAPS / OpenESB / Glasshfish as well.
Setting Up Hadoop and Cygwin
First thing to get up and running will be Hadoop, our environment runs on windows and there in lies the first problem. To run Hadoop on Windows you are going to need Cygwin.
Download: Hadoop and Cygwin.
Install Cygwin, just make sure to include the Openssh package.
Once installed, using the Cygwin command prompt: ssh-host-config
This is to setup the ssh configuration, reply yes to everything except if it asks
"This script plans to use cyg_server, Do you want to use a different name?" Then answer no.
There seems to be a couple issues with regards to permissions between Windows (Vista in my case), Cygwin and sshd.
Note: Be sure to add your Cygwin "\bin" folder to your windows path (else it will come back and bite you when trying to run your first map reduce job)
and typical to Windows, a reboot is required to get it all working.
So once that is done you should be able to start the ssh server: cygrunsrv -S sshd
Check that you can ssh to the localhost without a passphrase: ssh localhost
If that requires passphrase, run the following:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Now back to the Hadoop configuration:
Assuming that Hadoop was downloaded and unzipped into a working folder, ensure that the JAVA_HOME is set. Edit the [working folder]/conf/hadoop-env.sh.
The go into [working folder]/conf, and add the following to core-site.xml:
To mapred-site.xml add:
Go to the hadoop folder: cd /cygdrive/[drive]/[working folder]
format the dfs: bin/hadoop namenode -format
Execute the following: bin/start-all.sh
You should then have the following URLs available:
http://localhost:50070/
http://localhost:50030/
A Hadoop application is made up of one or more jobs. A job
consists of a configuration file and one or more Java classes, these will interact with the data that exists on the Hadoop distributed file system (HDFS).
Now to get those pesky log files into the HDFS. I created a little HDFS Wrapper class to allow me to interact with the file system. I have defaulted to my values (in core-site.xml).
HDFS Wrapper:
I also found a quick way to start searching the log file uploaded, is the Grep example included with Hadoop, and included it my HDFS test case below. Simple Wrapper Test:
Monday, November 22, 2010
Design Patterns in the JDK.
I saw an article (well more of a rant) the other day, by Rob Williams
Brain Drain in enterprise Dev. I have to say, I do agree with some of what he is saying. I know from my personal experience, I had spent a good 2 or so years just wallowing in the enterprise development world, not learning anything and actually losing my skills I developed before. The corporate confront zone is not conducive to eager technologists.
In this article he also stated:
"1 in 10 cant even pass a simple test like ‘which design pattern is used in the streams library that makes BufferedFileReader interchangeable with a FileReader?'"
I also tested it at work and I only had 1 out of the 8 people asked that got it right
Without much confidence, I had guessed Decorator based on "interchangeable". I then decided that was actually some worth sneaking into future interviews, and probably a good time to revise a little.
So I went scouring the internet to find all I could on the topic and I didn't actually find as much as I thought I would. Most of it came from BalusC at Stackoverflow, the rest was very scattered between blog posts, java ranch, some old pdf's and articles I had. I didn't take every single example of every single pattern I found, but rather the common ones.
This may be a good way for people to learn about patterns, quite often they are using them everyday without realizing.
Structural
Adapter:
This is used to convert the programming interface/class into that of another.
-java.util.Arrays#asList()
-javax.swing.JTable(TableModel)
-java.io.InputStreamReader(InputStream)
-java.io.OutputStreamWriter(OutputStream)
-javax.xml.bind.annotation.adapters.XmlAdapter#marshal()
-javax.xml.bind.annotation.adapters.XmlAdapter#unmarshal()
Bridge:
This decouples an abstraction from the implementation of its abstract operations, so that the abstraction and its implementation can vary independently.
-AWT (It provides an abstraction layer which maps onto the native OS the windowing support.)
-JDBC
Composite:
Lets clients treat individual objects and compositions of objects uniformly. So in other words methods on a type accepting the same type.
-javax.swing.JComponent#add(Component)
-java.awt.Container#add(Component)
-java.util.Map#putAll(Map)
-java.util.List#addAll(Collection)
-java.util.Set#addAll(Collection)
Decorator:
Attach additional responsibilities to an object dynamically and therefore it is also an alternative to subclassing. Can be seen when creating a type passes in the same type. This is actually used all over the JDK, the more you look the more you find, so the list below is definitely not complete.
-java.io.BufferedInputStream(InputStream)
-java.io.DataInputStream(InputStream)
-java.io.BufferedOutputStream(OutputStream)
-java.util.zip.ZipOutputStream(OutputStream)
-java.util.Collections#checked[List|Map|Set|SortedSet|SortedMap]()
Facade:
To provide a simplified interface to a group of components, interfaces, abstractions or subsystems.
-java.lang.Class
-javax.faces.webapp.FacesServlet
Flyweight:
Caching to support large numbers of smaller objects efficiently. I stumbled apon this a couple months back.
-java.lang.Integer#valueOf(int)
-java.lang.Boolean#valueOf(boolean)
-java.lang.Byte#valueOf(byte)
-java.lang.Character#valueOf(char)
Proxy:
The Proxy pattern is used to represent with a simpler object an object that is complex or time consuming to create.
-java.lang.reflect.Proxy
-RMI
Creational
Abstract factory:
To provide a contract for creating families of related or dependent objects without having to specify their concrete classes. It enables one to decouple an application from the concrete implementation of an entire framework one is using. This is also found all over the JDK and a lot of frameworks like Spring. They are simple to spot, any method that is used to create an object but still returns a interface or abstract class.
-java.util.Calendar#getInstance()
-java.util.Arrays#asList()
-java.util.ResourceBundle#getBundle()
-java.sql.DriverManager#getConnection()
-java.sql.Connection#createStatement()
-java.sql.Statement#executeQuery()
-java.text.NumberFormat#getInstance()
-javax.xml.transform.TransformerFactory#newInstance()
Builder:
Used simplify complex object creation by defining a class whose purpose is to build instances of another class. The builder pattern also allows for the implementation of a Fluent Interface.
-java.lang.StringBuilder#append()
-java.lang.StringBuffer#append()
-java.sql.PreparedStatement
-javax.swing.GroupLayout.Group#addComponent()
Factory method:
Simply a method that returns an actual type.
-java.lang.Proxy#newProxyInstance()
-java.lang.Object#toString()
-java.lang.Class#newInstance()
-java.lang.reflect.Array#newInstance()
-java.lang.reflect.Constructor#newInstance()
-java.lang.Boolean#valueOf(String)
-java.lang.Class#forName()
Prototype:
Allows for classes whose instances can create duplicates of themselves. This can be used when creating an instance of a class is very time-consuming or complex in some way, rather than creating new instances, you can make copies of the original instance and modify it.
-java.lang.Object#clone()
-java.lang.Cloneable
Singleton:
This tries to ensure that there is only a single instance of a class. I didn't find an example but another solution would be to use an Enum as Joshua Bloch suggests in Effective Java.
-java.lang.Runtime#getRuntime()
-java.awt.Toolkit#getDefaultToolkit()
-java.awt.GraphicsEnvironment#getLocalGraphicsEnvironment()
-java.awt.Desktop#getDesktop()
Behavioral
Chain of responsibility:
Allows for the decoupling between objects by passing a request from one object to the next in a chain until the request is recognized. The objects in the chain are different implementations of the same interface or abstract class.
-java.util.logging.Logger#log()
-javax.servlet.Filter#doFilter()
Command:
To wrap a command in an object so that it can be stored, passed into methods, and returned like any other object.
-java.lang.Runnable
-javax.swing.Action
Interpreter:
This pattern generally describes defining a grammar for that language and using that grammar to interpret statements in that format.
-java.util.Pattern
-java.text.Normalizer
-java.text.Format
Iterator:
To provide a consistent way to sequentially access items in a collection that is independent of and separate from the underlying collection.
-java.util.Iterator
-java.util.Enumeration
Mediator:
Used to reduce the number of direct dependencies between classes by introducing a single object that manages message distribution.
-java.util.Timer
-java.util.concurrent.Executor#execute()
-java.util.concurrent.ExecutorService#submit()
-java.lang.reflect.Method#invoke()
Memento:
This is a snapshot of an object’s state, so that the object can return to its original state without having to reveal it's content. Date does this by actually having a long value internally.
-java.util.Date
-java.io.Serializable
Null Object:
This can be used encapsulate the absence of an object by providing an alternative 'do nothing' behavior. It allows you to abstract the handling of null objects.
-java.util.Collections#emptyList()
-java.util.Collections#emptyMap()
-java.util.Collections#emptySet()
Observer:
Used to provide a way for a component to flexibly broadcast messages to interested receivers.
-java.util.EventListener
-javax.servlet.http.HttpSessionBindingListener
-javax.servlet.http.HttpSessionAttributeListener
-javax.faces.event.PhaseListener
State:
This allows you easily change an object’s behavior at runtime based on internal state.
-java.util.Iterator
-javax.faces.lifecycle.LifeCycle#execute()
Strategy:
Is intended to provide a means to define a family of algorithms, encapsulate each one as an object. These can then be flexibly passed in to change the functionality.
-java.util.Comparator#compare()
-javax.servlet.http.HttpServlet
-javax.servlet.Filter#doFilter()
Template method:
Allows subclasses to override parts of the method without rewriting it, also allows you to control which operations subclasses are required to override.
-java.util.Collections#sort()
-java.io.InputStream#skip()
-java.io.InputStream#read()
-java.util.AbstractList#indexOf()
Visitor:
To provide a maintainable, easy way to perform actions for a family of classes. Visitor centralizes the behaviors and allows them to be modified or extended without changing the classes they operate on.
-javax.lang.model.element.Element and javax.lang.model.element.ElementVisitor
-javax.lang.model.type.TypeMirror and javax.lang.model.type.TypeVisitor
Brain Drain in enterprise Dev. I have to say, I do agree with some of what he is saying. I know from my personal experience, I had spent a good 2 or so years just wallowing in the enterprise development world, not learning anything and actually losing my skills I developed before. The corporate confront zone is not conducive to eager technologists.
In this article he also stated:
"1 in 10 cant even pass a simple test like ‘which design pattern is used in the streams library that makes BufferedFileReader interchangeable with a FileReader?'"
I also tested it at work and I only had 1 out of the 8 people asked that got it right
Without much confidence, I had guessed Decorator based on "interchangeable". I then decided that was actually some worth sneaking into future interviews, and probably a good time to revise a little.
So I went scouring the internet to find all I could on the topic and I didn't actually find as much as I thought I would. Most of it came from BalusC at Stackoverflow, the rest was very scattered between blog posts, java ranch, some old pdf's and articles I had. I didn't take every single example of every single pattern I found, but rather the common ones.
This may be a good way for people to learn about patterns, quite often they are using them everyday without realizing.
Structural
Adapter:
This is used to convert the programming interface/class into that of another.
-java.util.Arrays#asList()
-javax.swing.JTable(TableModel)
-java.io.InputStreamReader(InputStream)
-java.io.OutputStreamWriter(OutputStream)
-javax.xml.bind.annotation.adapters.XmlAdapter#marshal()
-javax.xml.bind.annotation.adapters.XmlAdapter#unmarshal()
Bridge:
This decouples an abstraction from the implementation of its abstract operations, so that the abstraction and its implementation can vary independently.
-AWT (It provides an abstraction layer which maps onto the native OS the windowing support.)
-JDBC
Composite:
Lets clients treat individual objects and compositions of objects uniformly. So in other words methods on a type accepting the same type.
-javax.swing.JComponent#add(Component)
-java.awt.Container#add(Component)
-java.util.Map#putAll(Map)
-java.util.List#addAll(Collection)
-java.util.Set#addAll(Collection)
Decorator:
Attach additional responsibilities to an object dynamically and therefore it is also an alternative to subclassing. Can be seen when creating a type passes in the same type. This is actually used all over the JDK, the more you look the more you find, so the list below is definitely not complete.
-java.io.BufferedInputStream(InputStream)
-java.io.DataInputStream(InputStream)
-java.io.BufferedOutputStream(OutputStream)
-java.util.zip.ZipOutputStream(OutputStream)
-java.util.Collections#checked[List|Map|Set|SortedSet|SortedMap]()
Facade:
To provide a simplified interface to a group of components, interfaces, abstractions or subsystems.
-java.lang.Class
-javax.faces.webapp.FacesServlet
Flyweight:
Caching to support large numbers of smaller objects efficiently. I stumbled apon this a couple months back.
-java.lang.Integer#valueOf(int)
-java.lang.Boolean#valueOf(boolean)
-java.lang.Byte#valueOf(byte)
-java.lang.Character#valueOf(char)
Proxy:
The Proxy pattern is used to represent with a simpler object an object that is complex or time consuming to create.
-java.lang.reflect.Proxy
-RMI
Creational
Abstract factory:
To provide a contract for creating families of related or dependent objects without having to specify their concrete classes. It enables one to decouple an application from the concrete implementation of an entire framework one is using. This is also found all over the JDK and a lot of frameworks like Spring. They are simple to spot, any method that is used to create an object but still returns a interface or abstract class.
-java.util.Calendar#getInstance()
-java.util.Arrays#asList()
-java.util.ResourceBundle#getBundle()
-java.sql.DriverManager#getConnection()
-java.sql.Connection#createStatement()
-java.sql.Statement#executeQuery()
-java.text.NumberFormat#getInstance()
-javax.xml.transform.TransformerFactory#newInstance()
Builder:
Used simplify complex object creation by defining a class whose purpose is to build instances of another class. The builder pattern also allows for the implementation of a Fluent Interface.
-java.lang.StringBuilder#append()
-java.lang.StringBuffer#append()
-java.sql.PreparedStatement
-javax.swing.GroupLayout.Group#addComponent()
Factory method:
Simply a method that returns an actual type.
-java.lang.Proxy#newProxyInstance()
-java.lang.Object#toString()
-java.lang.Class#newInstance()
-java.lang.reflect.Array#newInstance()
-java.lang.reflect.Constructor#newInstance()
-java.lang.Boolean#valueOf(String)
-java.lang.Class#forName()
Prototype:
Allows for classes whose instances can create duplicates of themselves. This can be used when creating an instance of a class is very time-consuming or complex in some way, rather than creating new instances, you can make copies of the original instance and modify it.
-java.lang.Object#clone()
-java.lang.Cloneable
Singleton:
This tries to ensure that there is only a single instance of a class. I didn't find an example but another solution would be to use an Enum as Joshua Bloch suggests in Effective Java.
-java.lang.Runtime#getRuntime()
-java.awt.Toolkit#getDefaultToolkit()
-java.awt.GraphicsEnvironment#getLocalGraphicsEnvironment()
-java.awt.Desktop#getDesktop()
Behavioral
Chain of responsibility:
Allows for the decoupling between objects by passing a request from one object to the next in a chain until the request is recognized. The objects in the chain are different implementations of the same interface or abstract class.
-java.util.logging.Logger#log()
-javax.servlet.Filter#doFilter()
Command:
To wrap a command in an object so that it can be stored, passed into methods, and returned like any other object.
-java.lang.Runnable
-javax.swing.Action
Interpreter:
This pattern generally describes defining a grammar for that language and using that grammar to interpret statements in that format.
-java.util.Pattern
-java.text.Normalizer
-java.text.Format
Iterator:
To provide a consistent way to sequentially access items in a collection that is independent of and separate from the underlying collection.
-java.util.Iterator
-java.util.Enumeration
Mediator:
Used to reduce the number of direct dependencies between classes by introducing a single object that manages message distribution.
-java.util.Timer
-java.util.concurrent.Executor#execute()
-java.util.concurrent.ExecutorService#submit()
-java.lang.reflect.Method#invoke()
Memento:
This is a snapshot of an object’s state, so that the object can return to its original state without having to reveal it's content. Date does this by actually having a long value internally.
-java.util.Date
-java.io.Serializable
Null Object:
This can be used encapsulate the absence of an object by providing an alternative 'do nothing' behavior. It allows you to abstract the handling of null objects.
-java.util.Collections#emptyList()
-java.util.Collections#emptyMap()
-java.util.Collections#emptySet()
Observer:
Used to provide a way for a component to flexibly broadcast messages to interested receivers.
-java.util.EventListener
-javax.servlet.http.HttpSessionBindingListener
-javax.servlet.http.HttpSessionAttributeListener
-javax.faces.event.PhaseListener
State:
This allows you easily change an object’s behavior at runtime based on internal state.
-java.util.Iterator
-javax.faces.lifecycle.LifeCycle#execute()
Strategy:
Is intended to provide a means to define a family of algorithms, encapsulate each one as an object. These can then be flexibly passed in to change the functionality.
-java.util.Comparator#compare()
-javax.servlet.http.HttpServlet
-javax.servlet.Filter#doFilter()
Template method:
Allows subclasses to override parts of the method without rewriting it, also allows you to control which operations subclasses are required to override.
-java.util.Collections#sort()
-java.io.InputStream#skip()
-java.io.InputStream#read()
-java.util.AbstractList#indexOf()
Visitor:
To provide a maintainable, easy way to perform actions for a family of classes. Visitor centralizes the behaviors and allows them to be modified or extended without changing the classes they operate on.
-javax.lang.model.element.Element and javax.lang.model.element.ElementVisitor
-javax.lang.model.type.TypeMirror and javax.lang.model.type.TypeVisitor
Friday, November 19, 2010
Now with a new cleaner look...
I had a couple mails and comments stating that my blog theme made it hard to read, so for a complete reversal ... I went as clean as I could.
Monday, November 15, 2010
Learning to Drool... Part 2
In Part 1 I went through the basic syntax and requirements to get a rule developed and tested.
Now to extend that, the Drools documentation is actually quite good, there is just a ton of it, so I will try to just focus on some of the main topics.
First a little thing I had to do to get the rules to run from your tests using maven, the .drls are not in the classpath by default, a simple way around that was to add the following to the POM:
Now more rules scenarios and usages:
Collections:
Querying the contents of a can be done in 2 ways, contains and memberOf, the difference is that the collection used in conjunction with memberOf must be a variable.
The drl:
Regular Expressions:
You can use a regex as a selection criteria as well with the key words Matches and Not Matches.
The drl:
Global Variables:
You can define global variables, they should not be used as the are sometimes in code, to pass information between methods or in this case rules. They should rather be used to provide data or services that the rules use. An example would be something like an application specific logger, or perhaps constant lookup data loaded when the application starts.
The test:
The drl:
Rule Attributes:
On a rule you can specify attribute, there are a number of these. I'll just mention a couple handy ones (quoting the official documentation):
no-loop
default value: false
type: Boolean
When the rule's consequence modifies a fact it may cause the Rule to activate again, causing recursion. Setting no-loop to true means the attempt to create the Activation for the current set of data will be ignored.
salience
default value : 0
type : integer
Salience is a form of priority where rules with higher salience values are given higher priority when ordered in the Activation queue.
dialect
default value: as specified by the package
type: String
possible values: "java" or "mvel"
The dialect species the language to be used for any code expressions in the LHS or the RHS code block. Currently two dialects are available, Java and MVEL. While the dialect can be specified at the package level, this attribute allows the package definition to be overridden for a rule.
date-effective
default value: N/A
type: String, containing a date and time definition
A rule can only activate if the current date and time is after date-effective attribute.
date-expires
default value: N/A
type: String, containing a date and time definition
A rule cannot activate if the current date and time is after the date-expires attribute.
Guided Rule:
The guided rule editor seems to allow for everything you can do in code, just visually, and potentially more intuitively for those non developers. Only thing you need to do is make sure to have the objects you want to use imported in a .package in the same location as the created .brl file.
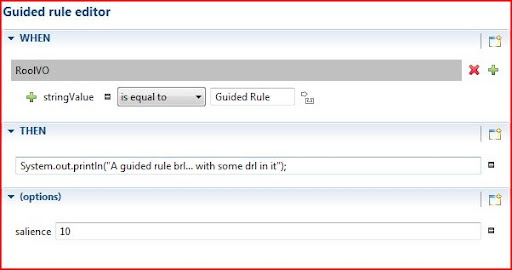
Decision Tables:
In my opinion the world actually runs on spreadsheets. We all like to think that it only functions because of us and our fancy applications, but truth be told the world would miss spreadsheets more than any other single application.
The business people giving us our requirements understand spread sheets, some of them better than us developers and this is the biggest single bonus on decision tables. The Drools decision table at first glance did look as if it would not be as simple to hand over to business users as the Quickrules one, but it is actually split quite clearly into "code" and "data"
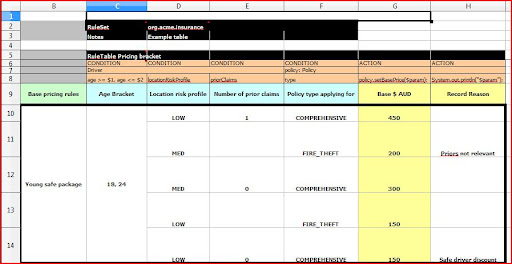
Now to breakdown a decision table into its parts...
When creating a decision table, the eclipse plugin gives you an example, I am going to work through that.
C2: Keyword ruleset, just to state that this spread sheet is a ruleset (package).
D2: The ruleset (package) name.
Under this row you can specify the following optional keywords:
Sequential - The cell to the right of this can be true or false. If true, then salience is used to ensure that rules fire from the top down.
Import - The cell to the right contains a comma separated list of classes to import.
Variables - The cell immediately to the right can contain global declarations which Drools supports. This is a type, followed by a variable name. (if multiple variables are needed, comma separate them).
C3/D4: Notes heading and the actual notes.
C5: The RuleTable keyword and name. The "RuleTable" keyword must appear on top of the first condition column. You can have multiple rule tables on a sheet, they must just be separated by a line.
C6: Marks the column as a CONDITION column, G6, does this for the ACTION. You need at least one of each for a table to be valid. If there is no data in a CONDITION column, then that condition does not apply.
Other column optional keywords are:
PRIORITY - This states that this column's values will set the salience
DURATION - This will set the duration values for the rule row.
NO-LOOP - Same as in the drl, this specifies if rule is not allowed to loop.
C7: This and subsequent columns in the row, define the actual variables referenced in the rule table.
C8: This and subsequent columns in the row specifies where we are getting the data from.
Row 9 and Column B are just labels / headings making the data simpler to understand, all the other fields and columns before there can be hidden as not to scare the "less technical". The table inside B9 is then were the specific rule data is defined, hopefully directly from the specification, by a non developer.
I have uploaded this project to my Google code project, incase anyone wants it. I had a little issue with the decision table because I run OpenOffice at home and not Microsoft Office, the plugin expects Excel, so it leaves a ugly little red X in my project, but it opens fine outside the IDE and still compiles in maven.
Part 3, I'll have a look at the Rule Flow, and start tackling the monster that is Guvnor
Now to extend that, the Drools documentation is actually quite good, there is just a ton of it, so I will try to just focus on some of the main topics.
First a little thing I had to do to get the rules to run from your tests using maven, the .drls are not in the classpath by default, a simple way around that was to add the following to the POM:
Now more rules scenarios and usages:
Collections:
Querying the contents of a can be done in 2 ways, contains and memberOf, the difference is that the collection used in conjunction with memberOf must be a variable.
The drl:
Regular Expressions:
You can use a regex as a selection criteria as well with the key words Matches and Not Matches.
The drl:
Global Variables:
You can define global variables, they should not be used as the are sometimes in code, to pass information between methods or in this case rules. They should rather be used to provide data or services that the rules use. An example would be something like an application specific logger, or perhaps constant lookup data loaded when the application starts.
The test:
The drl:
Rule Attributes:
On a rule you can specify attribute, there are a number of these. I'll just mention a couple handy ones (quoting the official documentation):
no-loop
default value: false
type: Boolean
When the rule's consequence modifies a fact it may cause the Rule to activate again, causing recursion. Setting no-loop to true means the attempt to create the Activation for the current set of data will be ignored.
salience
default value : 0
type : integer
Salience is a form of priority where rules with higher salience values are given higher priority when ordered in the Activation queue.
dialect
default value: as specified by the package
type: String
possible values: "java" or "mvel"
The dialect species the language to be used for any code expressions in the LHS or the RHS code block. Currently two dialects are available, Java and MVEL. While the dialect can be specified at the package level, this attribute allows the package definition to be overridden for a rule.
date-effective
default value: N/A
type: String, containing a date and time definition
A rule can only activate if the current date and time is after date-effective attribute.
date-expires
default value: N/A
type: String, containing a date and time definition
A rule cannot activate if the current date and time is after the date-expires attribute.
Guided Rule:
The guided rule editor seems to allow for everything you can do in code, just visually, and potentially more intuitively for those non developers. Only thing you need to do is make sure to have the objects you want to use imported in a .package in the same location as the created .brl file.
Decision Tables:
In my opinion the world actually runs on spreadsheets. We all like to think that it only functions because of us and our fancy applications, but truth be told the world would miss spreadsheets more than any other single application.
The business people giving us our requirements understand spread sheets, some of them better than us developers and this is the biggest single bonus on decision tables. The Drools decision table at first glance did look as if it would not be as simple to hand over to business users as the Quickrules one, but it is actually split quite clearly into "code" and "data"
Now to breakdown a decision table into its parts...
When creating a decision table, the eclipse plugin gives you an example, I am going to work through that.
C2: Keyword ruleset, just to state that this spread sheet is a ruleset (package).
D2: The ruleset (package) name.
Under this row you can specify the following optional keywords:
Sequential - The cell to the right of this can be true or false. If true, then salience is used to ensure that rules fire from the top down.
Import - The cell to the right contains a comma separated list of classes to import.
Variables - The cell immediately to the right can contain global declarations which Drools supports. This is a type, followed by a variable name. (if multiple variables are needed, comma separate them).
C3/D4: Notes heading and the actual notes.
C5: The RuleTable keyword and name. The "RuleTable" keyword must appear on top of the first condition column. You can have multiple rule tables on a sheet, they must just be separated by a line.
C6: Marks the column as a CONDITION column, G6, does this for the ACTION. You need at least one of each for a table to be valid. If there is no data in a CONDITION column, then that condition does not apply.
Other column optional keywords are:
PRIORITY - This states that this column's values will set the salience
DURATION - This will set the duration values for the rule row.
NO-LOOP - Same as in the drl, this specifies if rule is not allowed to loop.
C7: This and subsequent columns in the row, define the actual variables referenced in the rule table.
C8: This and subsequent columns in the row specifies where we are getting the data from.
Row 9 and Column B are just labels / headings making the data simpler to understand, all the other fields and columns before there can be hidden as not to scare the "less technical". The table inside B9 is then were the specific rule data is defined, hopefully directly from the specification, by a non developer.
I have uploaded this project to my Google code project, incase anyone wants it. I had a little issue with the decision table because I run OpenOffice at home and not Microsoft Office, the plugin expects Excel, so it leaves a ugly little red X in my project, but it opens fine outside the IDE and still compiles in maven.
Part 3, I'll have a look at the Rule Flow, and start tackling the monster that is Guvnor
Monday, November 8, 2010
Learning to Drool... Part 1
This series of posts will be about me getting to grips with JBoss Drools. The reasoning behind it is: SAP bought out my company's current rules engine and Drools is one alternative we will be looking into as soon as someone has the skills to get a proof of concept up.
Although there seems to be a fair amount of documentation, I always find it helps having walked through examples, which is what I am going to do here.Drools on first glance can be quite daunting, it is made up of :
Drools Expert (rule engine)
Being a developer this is where I will begin, the actual rules and implementation of them.
The other parts I'll get to later are:
Drools Guvnor (BRMS/BPMS)
Drools Flow (process/workflow)
Drools Fusion (event processing/temporal reasoning)
Drools Planner (automated planning)
So to begin.
For part 1, I just want to get my feet wet, I download only the Eclipse plugin and the binaries
Need to install the Eclipse plugin, used the update site. Unzip the binaries to a directory and withing the Eclipse plugin settings point to that directory.
The eclipse plugin will allow you to create a Drools Project and that includes the "Drools Library", but if you are using maven you need to point to the JBoss release repo for the Drools dependencies, The KnowledgeRuntimeLoggerFactory needs XStream which you can just get from the standard maven repo. Below is my POM:
To add a rule, on src/main/rules, Right click -> New -> Other... Drools/Rule Resource, be sure to choose the "individual rule". This leaves you with an empty drl file:
To understand and use the rule language, I read the Drools Documentation and the examples project.
What actually took me a little to grasp, was the basic syntax and how objects were handled in the rules and I did struggle to find anything that actually explains it simply so I will give it a shot.
A note on variable names.. they do not need to have the '$' but it was used in the example and without it quickly gets quite confusing.
Now to step through the parts of a rule:
The package, and import keyword are self explanatory, what happens after the when is not.
What is happening in "$vo : RoolVO( stringValue == "Learning to drool", $booleanVal : booleanValue )" broken down actually is:
stringValue == "Learning to drool" - This is a constraint that allows us to find all RoolVO objects known to the knowledge base that have the getStringValue() value equals to "Learning to drool". If there are multiple instances of RoolVO that comply we will run this rule more than once, these are also referred to as matched objects. You can also have multiple constraints separated by a ",".
$booleanVal : booleanValue - We are declaring a new local variable of type boolean called $booleanVal and gets it value from isBooleanValue.
$vo : RoolVO - We are declaring a new local variable of type RoolVO called $vo.
The next line:
"eval( $booleanVal )" - Evaluates the boolean variable, this needs to evaluate to true for the 'then' part of the rule to be called.
Then:
System.out.println( "First Rule" ); - Standard sys out.
$vo.setStringValue("Done."); - Sets the String value on the current RoolVO object that matched the constraints to Done.
The main classes / interfaces needed for a basic rule execution seem to be the following:
org.drools.KnowledgeBase and it's factory
org.drools.KnowledgeBaseFactory:
This is the repository of all the relevant knowledge definitions; it contains rules, processes, functions, type models.
org.drools.builder.KnowledgeBuilder and it's factory org.drools.builder.KnowledgeBuilderFactory:
Transforms / parses a source file (.drl, .xsl) into a KnowledgePackage that a KnowledgeBase can understand.
StatefulKnowledgeSession created by the KnowledgeBase .newStatefulKnowledgeSession();
This session is used to communicate with the actual rules engine.
To quote the drools JavaDocs:
StatefulKnowledgeSession is the most common way to interact with a rules engine. A StatefulKnowledgeSession allows the application to establish an iterative conversation with the engine, where the reasoning process may be triggered multiple times for the same set of data.
I wrote a simple test for the rule I described earlier.
To be honest, Drools is not nearly as intuitive as Quickrules was from what I have seen in this first task. However, in Part 2, I will start looking at using the rule flows, decision table functionality as well as the guided rules:

Those in partnership with the DSL (Domain Specific Language) construct hopefully do allow for more intuitive rules creation.
Although there seems to be a fair amount of documentation, I always find it helps having walked through examples, which is what I am going to do here.Drools on first glance can be quite daunting, it is made up of :
Drools Expert (rule engine)
Being a developer this is where I will begin, the actual rules and implementation of them.
The other parts I'll get to later are:
Drools Guvnor (BRMS/BPMS)
Drools Flow (process/workflow)
Drools Fusion (event processing/temporal reasoning)
Drools Planner (automated planning)
So to begin.
For part 1, I just want to get my feet wet, I download only the Eclipse plugin and the binaries
Need to install the Eclipse plugin, used the update site. Unzip the binaries to a directory and withing the Eclipse plugin settings point to that directory.
The eclipse plugin will allow you to create a Drools Project and that includes the "Drools Library", but if you are using maven you need to point to the JBoss release repo for the Drools dependencies, The KnowledgeRuntimeLoggerFactory needs XStream which you can just get from the standard maven repo. Below is my POM:
To add a rule, on src/main/rules, Right click -> New -> Other... Drools/Rule Resource, be sure to choose the "individual rule". This leaves you with an empty drl file:
To understand and use the rule language, I read the Drools Documentation and the examples project.
What actually took me a little to grasp, was the basic syntax and how objects were handled in the rules and I did struggle to find anything that actually explains it simply so I will give it a shot.
A note on variable names.. they do not need to have the '$' but it was used in the example and without it quickly gets quite confusing.
Now to step through the parts of a rule:
The package, and import keyword are self explanatory, what happens after the when is not.
What is happening in "$vo : RoolVO( stringValue == "Learning to drool", $booleanVal : booleanValue )" broken down actually is:
stringValue == "Learning to drool" - This is a constraint that allows us to find all RoolVO objects known to the knowledge base that have the getStringValue() value equals to "Learning to drool". If there are multiple instances of RoolVO that comply we will run this rule more than once, these are also referred to as matched objects. You can also have multiple constraints separated by a ",".
$booleanVal : booleanValue - We are declaring a new local variable of type boolean called $booleanVal and gets it value from isBooleanValue.
$vo : RoolVO - We are declaring a new local variable of type RoolVO called $vo.
The next line:
"eval( $booleanVal )" - Evaluates the boolean variable, this needs to evaluate to true for the 'then' part of the rule to be called.
Then:
System.out.println( "First Rule" ); - Standard sys out.
$vo.setStringValue("Done."); - Sets the String value on the current RoolVO object that matched the constraints to Done.
The main classes / interfaces needed for a basic rule execution seem to be the following:
org.drools.KnowledgeBase and it's factory
org.drools.KnowledgeBaseFactory:
This is the repository of all the relevant knowledge definitions; it contains rules, processes, functions, type models.
org.drools.builder.KnowledgeBuilder and it's factory org.drools.builder.KnowledgeBuilderFactory:
Transforms / parses a source file (.drl, .xsl) into a KnowledgePackage that a KnowledgeBase can understand.
StatefulKnowledgeSession created by the KnowledgeBase .newStatefulKnowledgeSession();
This session is used to communicate with the actual rules engine.
To quote the drools JavaDocs:
StatefulKnowledgeSession is the most common way to interact with a rules engine. A StatefulKnowledgeSession allows the application to establish an iterative conversation with the engine, where the reasoning process may be triggered multiple times for the same set of data.
I wrote a simple test for the rule I described earlier.
To be honest, Drools is not nearly as intuitive as Quickrules was from what I have seen in this first task. However, in Part 2, I will start looking at using the rule flows, decision table functionality as well as the guided rules:
Those in partnership with the DSL (Domain Specific Language) construct hopefully do allow for more intuitive rules creation.
Wednesday, November 3, 2010
Less code - More rules
Less code - More rules...
There I said it...Now before condemning me to the pits of hell let me add some context.
In large corporate financial development where systems are comprised of thousands of business rules and run in production for many years... rules, rules, rules are the key... more specifically the management of rules with a Rules engine and/or a BRMS(Business Rule Management System). Now I know, some people love them, some people hate them and some "wrote their own"... personally I think they add a huge amount of benefit when used within the correct context.
I have worked in an environment where we have both successfully and unsuccessfully used a BRMS(Yasutech Quickrules) in implementing countless rules, flows, decision tables over a 5 year period. Unfortunately Quickrules is no longer actively supported, SAP has squished them into SAP Netweaver BRM.
I work in the health insurance industry, and there is a vast amount of analysis, risk management and business rules that go into the "simple" act of getting a stay in hospital paid. What makes it even worse is that these rules change, and they change often, there a constant stream of changes due to legislation changes, overly smart actuaries or overly zealous marketing department announcements. All this creates an environment where there are literally thousands of volitile rules, calculations, scenarios. Now add the fact that large corporate applications like these sometimes live for a decade or more and having business rules spread between code, store procedures, data tables and web pages and you have a recipe for disaster. (These are the systems we fortunately get to rewrite them from time to time.)
Based on my experience over the last couple years; the biggest single benefit of a BRMS is simply "separation of concerns".
What this separation allows for is:
1. Rules to be developed, tested, and possibly even deployed on a different time
line from the application itself.
2. The use of different resources. We managed have both the architect and business analysts define, develop and test rules with very little effort from the developers. I know this is a scary concept, and we only did it after years of having everything in place but with the correct standards, peer review, testing and training it is a possibility.
3. More business involvement and ownership, having the ability to simply let the business owners work with their own spreadsheets and import them directly (into development environment) helped cut down on the red tape and actually made them think about their requirements for a change.
4. More quantifiable delivery segments and estimates for those pesky project managers.
One very important thing to note is that even though rules can be handled separately, they still need to be part of the development and quality processes. After all, the business rules (depending on system) are what it's all about in the end. Most of what we do in these financial corporate application is to facilitate the running of business rules. If anything there should be stricter control and quality assurance on the rules than on the code.
The second thing worth mentioning (which is also actually a by-product of the separation) is visibility of business rules to people that understand them. To be able to print out and sit with either the business analysts or the actual business representatives and visually discuss the flow and structure of the rules proved to be very helpful.
There are of course many other benefits to BRMSs auditing, performance and management, but to me the separation and visibility is were the real value lies.
So with Quickrules gone and with Ilog JRules and Blaze Advisor not available to the common man, I turn to Drools.
Over the next couple weeks I need to spend some time ... Learning to Drool...
On first glace Drools does seem a little daunting, split into :
Drools Guvnor (BRMS/BPMS)
Drools Expert (rule engine)
Drools Flow (process/workflow)
Drools Fusion (event processing/temporal reasoning)
Drools Planner..
Hopefully there is a simple, quick way to get to grips with it all as I would actually like to run a concurrent proof of concept on my next project to see how it compares.
There I said it...Now before condemning me to the pits of hell let me add some context.
In large corporate financial development where systems are comprised of thousands of business rules and run in production for many years... rules, rules, rules are the key... more specifically the management of rules with a Rules engine and/or a BRMS(Business Rule Management System). Now I know, some people love them, some people hate them and some "wrote their own"... personally I think they add a huge amount of benefit when used within the correct context.
I have worked in an environment where we have both successfully and unsuccessfully used a BRMS(Yasutech Quickrules) in implementing countless rules, flows, decision tables over a 5 year period. Unfortunately Quickrules is no longer actively supported, SAP has squished them into SAP Netweaver BRM.
I work in the health insurance industry, and there is a vast amount of analysis, risk management and business rules that go into the "simple" act of getting a stay in hospital paid. What makes it even worse is that these rules change, and they change often, there a constant stream of changes due to legislation changes, overly smart actuaries or overly zealous marketing department announcements. All this creates an environment where there are literally thousands of volitile rules, calculations, scenarios. Now add the fact that large corporate applications like these sometimes live for a decade or more and having business rules spread between code, store procedures, data tables and web pages and you have a recipe for disaster. (These are the systems we fortunately get to rewrite them from time to time.)
Based on my experience over the last couple years; the biggest single benefit of a BRMS is simply "separation of concerns".
What this separation allows for is:
1. Rules to be developed, tested, and possibly even deployed on a different time
line from the application itself.
2. The use of different resources. We managed have both the architect and business analysts define, develop and test rules with very little effort from the developers. I know this is a scary concept, and we only did it after years of having everything in place but with the correct standards, peer review, testing and training it is a possibility.
3. More business involvement and ownership, having the ability to simply let the business owners work with their own spreadsheets and import them directly (into development environment) helped cut down on the red tape and actually made them think about their requirements for a change.
4. More quantifiable delivery segments and estimates for those pesky project managers.
One very important thing to note is that even though rules can be handled separately, they still need to be part of the development and quality processes. After all, the business rules (depending on system) are what it's all about in the end. Most of what we do in these financial corporate application is to facilitate the running of business rules. If anything there should be stricter control and quality assurance on the rules than on the code.
The second thing worth mentioning (which is also actually a by-product of the separation) is visibility of business rules to people that understand them. To be able to print out and sit with either the business analysts or the actual business representatives and visually discuss the flow and structure of the rules proved to be very helpful.
There are of course many other benefits to BRMSs auditing, performance and management, but to me the separation and visibility is were the real value lies.
So with Quickrules gone and with Ilog JRules and Blaze Advisor not available to the common man, I turn to Drools.
Over the next couple weeks I need to spend some time ... Learning to Drool...
On first glace Drools does seem a little daunting, split into :
Drools Guvnor (BRMS/BPMS)
Drools Expert (rule engine)
Drools Flow (process/workflow)
Drools Fusion (event processing/temporal reasoning)
Drools Planner..
Hopefully there is a simple, quick way to get to grips with it all as I would actually like to run a concurrent proof of concept on my next project to see how it compares.
Monday, October 25, 2010
Top 7 of 97 Things Every Software Architect Should Know
Last week I commented on the 97 Things every programmer should know. I figured I would do the same for the 97 Things Every Software Architect Should Know. Initially I thought there may be some overlap between the 2, but they have done very well to focus each book on the targeted readers. I did however feel that quite a few of this "97 Things" were very similar in the principle they were trying to explain and so I grouped them under the relevant principle.
Before I start I just need to comment on the first chapter of the book:
Don't put your resume ahead of the requirements - Nitin Borwankar
I am not sure how I feel about this one. I understand the point and I do partially agree, but it also doesn't mean that the "latest shiny object in the latest shiny language or the latest shiny paradigm" isn't the best thing for the company or project. The choice of some new technology for a solution is a very difficult one and should not be taken lightly. Staying with what is already known is definitely the safer option and possibly the correct choice for a project or company in the short term, but when does this become something that actually does more harm than good?
Moving along to my top 7 things:
1. Understand The Business Domain - Mark Richards
Us "systems" folk, often experts in our own field don't always spend the time to understand the actual business we are involved in e.g. insurance, finance, marketing. To be a more effective software architect appropriate industry knowledge is as important as staying up to date with tech.
2. Before anything, an architect is a developer - Mike Brown
"If you design it, you should be able to code it."
I am a firm believer in the above statement. Architects sometimes don't have the time or the will to keep their developer skills current and over time let these skills atrophy. This can then lead to grand designs, with ugly implementations with unhappy developers
3. Dealing with Developers
There were a couple topics on interaction with developers, I decided to group them into 1 point:
Find and retain passionate problem solvers - Chad LaVigne
Give developers autonomy - Philip Nelson
Empower developers - Timothy High
An architect may be a developer, but he also needs to lead them, like it or not, architects by default have a leadership role to play when it comes to the developers on their project. Developers left to their own devices will run wild (we always do ;) ). So as with most things in software architecture it's all about balance:
4. Performance
There are 2 topics about performance:
It's never too early to think about performance - Rebecca Parsons
Application architecture determines application performance - Randy Stafford
In my current environment where transaction processing times are tightly monitored and contracted with SLAs that have financial implications, performance is always top priority. However in many other teams / projects / companies I have worked in the emphasis on system performance is almost always left to the end, and sometimes no amount of hardware is going to solve the problem.
5. Record your rationale - Timothy High
This is something that I feel is often neglected. Quite recently a project that I had been involved in for a long time hit the spotlight for all the wrong reasons: customer, user and management dissatisfaction. The first thing to be questioned was not the analysis, requirements, testing, management or expectations, but rather the architecture. Documentation discussing all the decisions, options looked at and reason for options taken would have been valuable. When things go fine, no one will even know about the document, but when things turn bad as they sometimes do having justification and documentation for all the major decisions will be a lifesaver.
6. Stand Up! - Udi Dahan
"The easiest way to more than double your effectiveness when communicating ideas is quite simply to stand up."
This is more of a general point rather than one just for architects, anyone attempting to influence people and situations can benefit from this principle.
7. Great software is not built, it is grown - Bill de hora
"The single biggest predictor of software failure is size; on reflection there's almost no benefit to be had from starting with a large system design."
"Have a grand vision, but not a grand design."
It is all too tempting to jump in and design the total solution. By starting with a basic, small, solid system implementation and growing from that base over the life of the project always with a grand vision in mind, you allow the software to evolve rather than just stuck together. Evolution turned out ok for us, no reason it shouldn't be the same for software.
This approach should not be confused with prototyping, there shouldn't be any quality shortcuts taken and it shouldn't be thrown away.
All the contributions for both books are actually available on the O'reilly site:
Programmer
Architect
There are also a number of "things" not included in the books available on the wiki.
//ignore the next bit
Technorati claim:987BEU5BKS8H
Before I start I just need to comment on the first chapter of the book:
Don't put your resume ahead of the requirements - Nitin Borwankar
I am not sure how I feel about this one. I understand the point and I do partially agree, but it also doesn't mean that the "latest shiny object in the latest shiny language or the latest shiny paradigm" isn't the best thing for the company or project. The choice of some new technology for a solution is a very difficult one and should not be taken lightly. Staying with what is already known is definitely the safer option and possibly the correct choice for a project or company in the short term, but when does this become something that actually does more harm than good?
Moving along to my top 7 things:
1. Understand The Business Domain - Mark Richards
Us "systems" folk, often experts in our own field don't always spend the time to understand the actual business we are involved in e.g. insurance, finance, marketing. To be a more effective software architect appropriate industry knowledge is as important as staying up to date with tech.
2. Before anything, an architect is a developer - Mike Brown
"If you design it, you should be able to code it."
I am a firm believer in the above statement. Architects sometimes don't have the time or the will to keep their developer skills current and over time let these skills atrophy. This can then lead to grand designs, with ugly implementations with unhappy developers
3. Dealing with Developers
There were a couple topics on interaction with developers, I decided to group them into 1 point:
Find and retain passionate problem solvers - Chad LaVigne
Give developers autonomy - Philip Nelson
Empower developers - Timothy High
An architect may be a developer, but he also needs to lead them, like it or not, architects by default have a leadership role to play when it comes to the developers on their project. Developers left to their own devices will run wild (we always do ;) ). So as with most things in software architecture it's all about balance:
if (Too much control)I believe the relationship between developers and architects is one of the many crucial factors in the success of a project.
developers = unhappy
else if (Too little control)
customers = unhappy
if(developers or customers are unhappy)
result = bad
4. Performance
There are 2 topics about performance:
It's never too early to think about performance - Rebecca Parsons
Application architecture determines application performance - Randy Stafford
In my current environment where transaction processing times are tightly monitored and contracted with SLAs that have financial implications, performance is always top priority. However in many other teams / projects / companies I have worked in the emphasis on system performance is almost always left to the end, and sometimes no amount of hardware is going to solve the problem.
5. Record your rationale - Timothy High
This is something that I feel is often neglected. Quite recently a project that I had been involved in for a long time hit the spotlight for all the wrong reasons: customer, user and management dissatisfaction. The first thing to be questioned was not the analysis, requirements, testing, management or expectations, but rather the architecture. Documentation discussing all the decisions, options looked at and reason for options taken would have been valuable. When things go fine, no one will even know about the document, but when things turn bad as they sometimes do having justification and documentation for all the major decisions will be a lifesaver.
6. Stand Up! - Udi Dahan
"The easiest way to more than double your effectiveness when communicating ideas is quite simply to stand up."
This is more of a general point rather than one just for architects, anyone attempting to influence people and situations can benefit from this principle.
7. Great software is not built, it is grown - Bill de hora
"The single biggest predictor of software failure is size; on reflection there's almost no benefit to be had from starting with a large system design."
"Have a grand vision, but not a grand design."
It is all too tempting to jump in and design the total solution. By starting with a basic, small, solid system implementation and growing from that base over the life of the project always with a grand vision in mind, you allow the software to evolve rather than just stuck together. Evolution turned out ok for us, no reason it shouldn't be the same for software.
This approach should not be confused with prototyping, there shouldn't be any quality shortcuts taken and it shouldn't be thrown away.
All the contributions for both books are actually available on the O'reilly site:
Programmer
Architect
There are also a number of "things" not included in the books available on the wiki.
//ignore the next bit
Technorati claim:987BEU5BKS8H
Monday, October 18, 2010
Top 9 of 97 Things every programmer should know
I recently finished 97 Things every programmer should know. Well to be completely honest I did skim over a couple of the 97, but all and all this was a very nice compilation of thoughts and topics about software development from very experienced authors. Well worth a read.
A couple of the "97 Things" discussed, stood out more than the others, the following would be the ones I rank as my top 9.
1. The Boy Scout Rule - Robert C. Martin (Uncle Bob)
"You don’t have to make every module perfect before you check it in. You simply have to make it a little bit better than when you checked it out."
To be honest this is not something I have followed throughout my career, and although I certainly try improve code where I can, I never did it per check-in. I do however feel that it is an awesome principle and should be something that is actually part of a code review process. It is all to easy to just say:
"It was like that already"
"that nasty code was there for years, I am not going to touch it."
"It never had any tests"
I work in a corporate environment were applications often last for 4-10 years. If part of the process is always to just make something a little better, everything from deleting unused code to writing a single extra unit test, year after year... it will end up with saving a lot of people a lot of time and money.
2. Beauty Is in Simplicity - Jørn Ølmheim
"The bottom line is that beautiful code is simple code."
Over the years this has become particularly important to me. Earlier in my career, especially when starting somewhere new I would design the crap out of something.
It would be: "Welcome to the school of over-engineering", everything would be abstracted to the nth degree, there would be patterns for the patterns, interfaces on interfaces for the abstractions and a huge amount of code and components catering for every "what if" that ever existed, that only I understood. All of this would lead to very "fancy" code, and me stroking my ego, but at what cost?
Only the minor little one: an utter nightmare to maintain. I have for a while now favored the simplest implementation of almost any solution, even if it is not necessarily the prefect technical implementation. In the world of long living software, maintainability should quite often outweigh other concerns.
3. Step Back and Automate, Automate, Automate - Cay Horstmann
I believe in automating everything possible: builds, deploys, code analysis, unit testing, functional testing, integration testing. None of us actually want to look at that stuff everyday and automation is the only way to get away from that. Can't say automate enough. Automate, Automate, Automate.
4. Continuous Learning - Clint Shank
This is a very important topic, we are in a industry that is constantly growing, changing, shifting and as a programmer you need to be learning and improving yourself wherever you can. It's very easy to get into a comfort zone and just rest on your laurels, I did that for a couple years, and I do regret it now.
Things I am trying to do to keep up and would recommend:
1. Get a Kindle... then buy & read books.
2. Use Google Reader add the popular blogs and website RSS feeds for your specific field as well as a couple outside your field that interest you.
3. Start a blog, by putting my code and thoughts out there, I put in more effort knowing that it's going to visible than if I just wrote the code/article for myself. I also force myself to do 1 - 2 posts a week, ensuring that I must always find new content to learn about.
4. Join an open source community, we generally don't get to do enough "technical" development in our corporate environments.
5. Check Your Code First Before Looking to Blame Others - Allan Kelly
Exactly what it the title says, we all look to put the blame on anything other than our "perfect" code. Everything from the OS to the network guys, the DBAs to the JVM, 3rd party libraries to other teams' interfaces are always blamed first. This often leads to countless hours of wasted effort, or completely avoiding the issue that eventually comes back to bite you in the butt. Most of us can mention moments where we have done this, it's frighteningly common.
6. Hard Work Does Not Pay Off - Olve Maudal
"truth is that by working less, you might achieve more"
"If you are trying to be focused and “productive” for more than 30 hours a week, you
are probably working too hard."
I couldn't agree more with Olve Maudal. A lot of us have been there, we have spent the days, weeks, months at work, but we often don't see the negative sides of what happens when you work 50-70 hours a week. Everything from common logic to motivation and team dynamics go out the window. Even if the short term goals are achieved, quite often the long term repercussions are a lot worse. No one goes back and see's why they have to re-write a system 4 years down the line because the architecture or code is failing. I'd love to know how many of those were because of ludicrous hours and impossible time lines. I can think of at least 2 "re-writes" that I was involved in where you could see it was the result of long hours. People you know to write great code end up hacking solutions at 1am in the morning.
There are times and there always will be, where a couple extra hours are required, just try keep them down to a minimum.
7. Comment Only What the Code Cannot Say - Kevlin Henney
Exactly that... Don't tell another programmer what he can see in the code. Comments stating the business reason or requirement behind a particular complex algorithm is a lot more useful than //loop through the outcomes and add 1.
8. Know Your IDE - Heinz Kabutz
Something a lot of us are guilty of, we spend a couple hours a day in our IDE, learn the shortcuts, learn the features, we probably couldn't begin to calculate the time that would be saved if everyone used their IDE to it's full potential.
9. Learn to Estimate - Giovanni Asproni
I feel this is something that comes with experience, I pride myself on my estimates and over the years I have tried to nurture this "skill". I have a couple points I would like to share on how I get better estimates:
1. Be honest with yourself, make sure you know what you think you know, and openly admit what you don't. This is the quickest way to end up in trouble.
2. Keep track of what you do and how long it, not necessarily for the project manager, but for yourself, see point 1.
3. Don't rely on other peoples perceived skills and timing, see point 1.
Will try get through the rest of 97 Things Every Software Architect Should Know in the next week or so, will be interesting to see how it compares to the programmer one and how much overlaps.
A couple of the "97 Things" discussed, stood out more than the others, the following would be the ones I rank as my top 9.
1. The Boy Scout Rule - Robert C. Martin (Uncle Bob)
"You don’t have to make every module perfect before you check it in. You simply have to make it a little bit better than when you checked it out."
To be honest this is not something I have followed throughout my career, and although I certainly try improve code where I can, I never did it per check-in. I do however feel that it is an awesome principle and should be something that is actually part of a code review process. It is all to easy to just say:
"It was like that already"
"that nasty code was there for years, I am not going to touch it."
"It never had any tests"
I work in a corporate environment were applications often last for 4-10 years. If part of the process is always to just make something a little better, everything from deleting unused code to writing a single extra unit test, year after year... it will end up with saving a lot of people a lot of time and money.
2. Beauty Is in Simplicity - Jørn Ølmheim
"The bottom line is that beautiful code is simple code."
Over the years this has become particularly important to me. Earlier in my career, especially when starting somewhere new I would design the crap out of something.
It would be: "Welcome to the school of over-engineering", everything would be abstracted to the nth degree, there would be patterns for the patterns, interfaces on interfaces for the abstractions and a huge amount of code and components catering for every "what if" that ever existed, that only I understood. All of this would lead to very "fancy" code, and me stroking my ego, but at what cost?
Only the minor little one: an utter nightmare to maintain. I have for a while now favored the simplest implementation of almost any solution, even if it is not necessarily the prefect technical implementation. In the world of long living software, maintainability should quite often outweigh other concerns.
3. Step Back and Automate, Automate, Automate - Cay Horstmann
I believe in automating everything possible: builds, deploys, code analysis, unit testing, functional testing, integration testing. None of us actually want to look at that stuff everyday and automation is the only way to get away from that. Can't say automate enough. Automate, Automate, Automate.
4. Continuous Learning - Clint Shank
This is a very important topic, we are in a industry that is constantly growing, changing, shifting and as a programmer you need to be learning and improving yourself wherever you can. It's very easy to get into a comfort zone and just rest on your laurels, I did that for a couple years, and I do regret it now.
Things I am trying to do to keep up and would recommend:
1. Get a Kindle... then buy & read books.
2. Use Google Reader add the popular blogs and website RSS feeds for your specific field as well as a couple outside your field that interest you.
3. Start a blog, by putting my code and thoughts out there, I put in more effort knowing that it's going to visible than if I just wrote the code/article for myself. I also force myself to do 1 - 2 posts a week, ensuring that I must always find new content to learn about.
4. Join an open source community, we generally don't get to do enough "technical" development in our corporate environments.
5. Check Your Code First Before Looking to Blame Others - Allan Kelly
Exactly what it the title says, we all look to put the blame on anything other than our "perfect" code. Everything from the OS to the network guys, the DBAs to the JVM, 3rd party libraries to other teams' interfaces are always blamed first. This often leads to countless hours of wasted effort, or completely avoiding the issue that eventually comes back to bite you in the butt. Most of us can mention moments where we have done this, it's frighteningly common.
6. Hard Work Does Not Pay Off - Olve Maudal
"truth is that by working less, you might achieve more"
"If you are trying to be focused and “productive” for more than 30 hours a week, you
are probably working too hard."
I couldn't agree more with Olve Maudal. A lot of us have been there, we have spent the days, weeks, months at work, but we often don't see the negative sides of what happens when you work 50-70 hours a week. Everything from common logic to motivation and team dynamics go out the window. Even if the short term goals are achieved, quite often the long term repercussions are a lot worse. No one goes back and see's why they have to re-write a system 4 years down the line because the architecture or code is failing. I'd love to know how many of those were because of ludicrous hours and impossible time lines. I can think of at least 2 "re-writes" that I was involved in where you could see it was the result of long hours. People you know to write great code end up hacking solutions at 1am in the morning.
There are times and there always will be, where a couple extra hours are required, just try keep them down to a minimum.
7. Comment Only What the Code Cannot Say - Kevlin Henney
Exactly that... Don't tell another programmer what he can see in the code. Comments stating the business reason or requirement behind a particular complex algorithm is a lot more useful than //loop through the outcomes and add 1.
8. Know Your IDE - Heinz Kabutz
Something a lot of us are guilty of, we spend a couple hours a day in our IDE, learn the shortcuts, learn the features, we probably couldn't begin to calculate the time that would be saved if everyone used their IDE to it's full potential.
9. Learn to Estimate - Giovanni Asproni
I feel this is something that comes with experience, I pride myself on my estimates and over the years I have tried to nurture this "skill". I have a couple points I would like to share on how I get better estimates:
1. Be honest with yourself, make sure you know what you think you know, and openly admit what you don't. This is the quickest way to end up in trouble.
2. Keep track of what you do and how long it, not necessarily for the project manager, but for yourself, see point 1.
3. Don't rely on other peoples perceived skills and timing, see point 1.
Will try get through the rest of 97 Things Every Software Architect Should Know in the next week or so, will be interesting to see how it compares to the programmer one and how much overlaps.
Monday, October 11, 2010
Creating your own custom Spring configuration.
Recently I volunteered myself to do some of the Spring integration for Hazelcast, for one main reason actually.. I had always wondered how to actually do that. It is something you don't get to do often in a corporate working environment. As with most things Spring related it actually turned out to be very simple.
First thing I needed to do was define a schema for the Hazelcast xml config. If you want to add your custom XML configuration into Springs', it will require that you have a schema for the specific XML.
So what is the quickest way to get started on a schema? Altova XML Spy, it generates a basic XSD form a sample XML which takes care of about 40% of the actual work. Then it's all about the details, min / max constraints, enumerations, defaults, attributes and documentation. I believe XSDs should be verbose, so the version below is not 100% complete but it is a good starting point.
I am not going to add the XSD to this post as is quite long and doesn't add much with regards to the actual Spring integration. If interested, it is available here...
On the Spring side you need the following:
1. An implementation of: NamespaceHandlerSupport, this basically tells Spring when it finds "hazelcast" use the "HazelcastBeanDefinitionParser".
2. An implementation of: AbstractSimpleBeanDefinitionParser. This implementation actually processes the XML from the Spring application config. You need to override
getBeanClass and doParse methods, to specify what type of object and how to create it respectively.
3. 2 files in the META-INF
3.1. A spring.handlers file containing the namespace and the NamespaceHandlerSupport implementation (in my case):
http\://www.hazelcast.com/schema/config=com.hazelcast.spring.HazelcastNamespaceHandler
3.2. A spring.schemas file containing the location of the schema:
http\://www.hazelcast.com/schema/config/hazelcast-basic.xsd=hazelcast-basic.xsd
and that is it...
The XML you described in your XSD is now available to be used within your the Spring config.
The example below is a Hazelcast map cache config, which can then be injected where required as ref="config".
The source and tests for this are available in the Hazelcast code project here.
First thing I needed to do was define a schema for the Hazelcast xml config. If you want to add your custom XML configuration into Springs', it will require that you have a schema for the specific XML.
So what is the quickest way to get started on a schema? Altova XML Spy, it generates a basic XSD form a sample XML which takes care of about 40% of the actual work. Then it's all about the details, min / max constraints, enumerations, defaults, attributes and documentation. I believe XSDs should be verbose, so the version below is not 100% complete but it is a good starting point.
I am not going to add the XSD to this post as is quite long and doesn't add much with regards to the actual Spring integration. If interested, it is available here...
On the Spring side you need the following:
1. An implementation of: NamespaceHandlerSupport, this basically tells Spring when it finds "hazelcast" use the "HazelcastBeanDefinitionParser".
2. An implementation of: AbstractSimpleBeanDefinitionParser. This implementation actually processes the XML from the Spring application config. You need to override
getBeanClass and doParse methods, to specify what type of object and how to create it respectively.
3. 2 files in the META-INF
3.1. A spring.handlers file containing the namespace and the NamespaceHandlerSupport implementation (in my case):
http\://www.hazelcast.com/schema/config=com.hazelcast.spring.HazelcastNamespaceHandler
3.2. A spring.schemas file containing the location of the schema:
http\://www.hazelcast.com/schema/config/hazelcast-basic.xsd=hazelcast-basic.xsd
and that is it...
The XML you described in your XSD is now available to be used within your the Spring config.
The example below is a Hazelcast map cache config, which can then be injected where required as ref="config".
The source and tests for this are available in the Hazelcast code project here.
Tuesday, October 5, 2010
Spring 3: Spring Expression Language - SpEL
I realized that I have covered most of the major functions in the Spring 3 release, but completely overlooked SpEL. Now even though I am a huge Spring fan, all this functionality does actually scare me a little bit. To often have I seen people hang themselves with awesome, innocent looking ropes just like this one. Soon there will be some project that needs to be "dynamic" and some person/consultant/architect/developer will have this amazing idea and place code somewhere they can edit it externally. Then this SpEL can read this and "dynamically do stuff"...
(I am pretty sure that I have been that "person" somewhere in my career, it all feels horribly familiar.)
And all of that only comes at the price of some poor developers' sanity trying to maintain it. To be fair, this view is purely based on personal experiences and maybe slightly unjustified, but I have seen my share of good ideas gone bad in my time and it feels like SpEL is wide open for misuse.
Putting my concerns aside and refocusing on: it's something new , it's shiny and Spring-made so I obviously can't resist trying it out.
First I go digging for information to answer: "What is SpEL, Spring Expression Language?"
A quick summary of what I find:
It is an expression language that supports querying and manipulating objects at runtime. It can be used as part of the standard configuration, XML or annotation based, but can also be evaluated directly by the application code. It allows you to overcome the limitation of using only fixed values. It can be used for bean definitions in both XML- and annotation-based configurations. There is a facility to access system, environment and context parameters.
I have just covered thing that I would generally need or have run into... there is however quite a bit more information within the Spring documentation
So using Maven first thing I needed was to add following:
Using SpEL in Code:
Below I have examples code of: Setting a value, Calling a constructor, creating variables, calling a static function, all the basic operators, the instanceof operator and even the ternary if.
Using SpEL in XML Config: As with the Java code, here is the same functionality within you Spring application XML.
Using SpEL in Annotations:
And then again will the @Value annotation.
(I am pretty sure that I have been that "person" somewhere in my career, it all feels horribly familiar.)
And all of that only comes at the price of some poor developers' sanity trying to maintain it. To be fair, this view is purely based on personal experiences and maybe slightly unjustified, but I have seen my share of good ideas gone bad in my time and it feels like SpEL is wide open for misuse.
Putting my concerns aside and refocusing on: it's something new , it's shiny and Spring-made so I obviously can't resist trying it out.
First I go digging for information to answer: "What is SpEL, Spring Expression Language?"
A quick summary of what I find:
It is an expression language that supports querying and manipulating objects at runtime. It can be used as part of the standard configuration, XML or annotation based, but can also be evaluated directly by the application code. It allows you to overcome the limitation of using only fixed values. It can be used for bean definitions in both XML- and annotation-based configurations. There is a facility to access system, environment and context parameters.
I have just covered thing that I would generally need or have run into... there is however quite a bit more information within the Spring documentation
So using Maven first thing I needed was to add following:
Using SpEL in Code:
Below I have examples code of: Setting a value, Calling a constructor, creating variables, calling a static function, all the basic operators, the instanceof operator and even the ternary if.
Using SpEL in XML Config: As with the Java code, here is the same functionality within you Spring application XML.
Using SpEL in Annotations:
And then again will the @Value annotation.
Thursday, September 23, 2010
Guice & Hazelcast.... Method Caching Interceptor
A couple days back I did Spring, AspectJ, Hazelcast Method Caching Aspect and I received an anonymous question on how to do the same thing in Guice I had heard of Guice, I knew what it was, but... I have been a Spring zealot for many years now, so my first reaction was:
What??? Guice? me?? ... Not use Spring? ... why would you ever not do this is Spring?... after a bit more whining I finally found myself saying "Oh ok, let me do it in this Spring wannabe "Juice" framework, just to prove that Spring is better."
All I can say is dammit! I hate being wrong ... the Guice is sweet. It took me about an hour to go from never using it before to having this AOP Method Cache Interceptor project done. A lot of that time was me being a typical developer and playing rather than actually reading the docs. In other words, it's simple, and that is always a good thing.
Now before someone takes this the wrong way: I know Spring does a lot more, Guice is focused on DI, Spring integrates with more, most of the popular Google apps run on Guice so it is rock solid etc. etc... I am not doing this as a comparison and definitely don't want to choose sides, but rather just showing another way of doing something.
I will only be posting the interesting bits of this project here, the full source is available here :
Source Code
First thing, Guice is available in the Maven repo and they recommend using that rather than the google.code site. The POM for this project:
Guice (as they say in their documentation) takes full advantage of annotations and generics. So for this project I created a @Cacheable interface to allow me to annotate the methods I wanted cached.
To configure Guice you need to extend an AbstractModule, this is where you configure what gets injected where by what. In the example below I use a construct called a Provider to allow me to use the Hazelcast factory to inject and instance. One other important thing to note in the code below is the "requestInjection(cache)" when injecting into interceptors you need to specify that in order to that injection before actually using the interceptor.
The AbstractModule:
And lastly for the actual interceptor. Right at the bottom of the source below you will see the @CacheName interface, this is one of a number of ways to map configuration values to be injected. The interceptor implements MethodInterceptor and you get all the required information about the method execution from the MethodInvocation parameter.
So there you go Mr Anonymous, hope it helps.
What??? Guice? me?? ... Not use Spring? ... why would you ever not do this is Spring?... after a bit more whining I finally found myself saying "Oh ok, let me do it in this Spring wannabe "Juice" framework, just to prove that Spring is better."
All I can say is dammit! I hate being wrong ... the Guice is sweet. It took me about an hour to go from never using it before to having this AOP Method Cache Interceptor project done. A lot of that time was me being a typical developer and playing rather than actually reading the docs. In other words, it's simple, and that is always a good thing.
Now before someone takes this the wrong way: I know Spring does a lot more, Guice is focused on DI, Spring integrates with more, most of the popular Google apps run on Guice so it is rock solid etc. etc... I am not doing this as a comparison and definitely don't want to choose sides, but rather just showing another way of doing something.
I will only be posting the interesting bits of this project here, the full source is available here :
Source Code
First thing, Guice is available in the Maven repo and they recommend using that rather than the google.code site. The POM for this project:
Guice (as they say in their documentation) takes full advantage of annotations and generics. So for this project I created a @Cacheable interface to allow me to annotate the methods I wanted cached.
To configure Guice you need to extend an AbstractModule, this is where you configure what gets injected where by what. In the example below I use a construct called a Provider to allow me to use the Hazelcast factory to inject and instance. One other important thing to note in the code below is the "requestInjection(cache)" when injecting into interceptors you need to specify that in order to that injection before actually using the interceptor.
The AbstractModule:
And lastly for the actual interceptor. Right at the bottom of the source below you will see the @CacheName interface, this is one of a number of ways to map configuration values to be injected. The interceptor implements MethodInterceptor and you get all the required information about the method execution from the MethodInvocation parameter.
So there you go Mr Anonymous, hope it helps.
Monday, September 20, 2010
Spring, AspectJ, Hazelcast Method Caching Aspect
After my recent discovery of Hazelcast, I decided to update my caching aspect project to include a Hazelcast implementation.
The source code for this project is available here
For more information please refer to the actual source or my original Ehcache post. The main difference here is that the Hazelcast implementation is by default a distributed cache, and takes advantage of all the other functionality that Hazelcast provides.
The main points of interest for this implementation are:
- The actual aspect class. See code below.
- The application context. See xml below.
- The Hazelcast configuration. I am using the default Hazelcast configuration, located in the hazelcast-version.jar. To use a custom one, you can define a hazelcast.xml and inject it via Spring.
- The CacheKeyStrategy in the code below is an interface defined to allow key generation for the cache for specific requirements. There is a default implementation that simply sorts and uses hashcodes of the values in the class. You can define a strategy per type you want to cache.
note: java docs only removed for size of post
The aspect:
The application context:
The test case:
The source code for this project is available here
For more information please refer to the actual source or my original Ehcache post. The main difference here is that the Hazelcast implementation is by default a distributed cache, and takes advantage of all the other functionality that Hazelcast provides.
The main points of interest for this implementation are:
- The actual aspect class. See code below.
- The application context. See xml below.
- The Hazelcast configuration. I am using the default Hazelcast configuration, located in the hazelcast-version.jar. To use a custom one, you can define a hazelcast.xml and inject it via Spring.
- The CacheKeyStrategy in the code below is an interface defined to allow key generation for the cache for specific requirements. There is a default implementation that simply sorts and uses hashcodes of the values in the class. You can define a strategy per type you want to cache.
note: java docs only removed for size of post
The aspect:
The application context:
The test case:
Monday, September 13, 2010
Hazelcast - a simple distributed caching alternative
I have over the last couple years used EhCache either via Spring (with AOP) or having it configured as hibernates' cache. I have never had the time or the need to look into the whole distributed caching available with Terracotta. However I recently stumbled on to Hazelcast and read the following:
"Hazelcast is pure Java. JVMs that are running Hazelcast will dynamically cluster. Although by default Hazelcast will use multicast for discovery, it can also be configured to only use TCP/IP for environments where multicast is not available or preferred. Communication among cluster members is always TCP/IP with Java NIO beauty. Default configuration comes with 1 backup so if one node fails, no data will be lost. It is as simple as using java.util.{Queue, Set, List, Map}. Just add the hazelcast.jar into your classpath and start coding."
I was instantly intrigued. So it sounds simple enough...Open IDE...jump in... being a maven fan, I figure, why download and manually "install" when you can just use maven, so I search around a little and add the following to a pom.
Edit: 1.8.4 is now outdated check http://www.hazelcast.com/downloads.jsp for the latest.
From the online documentation, I saw there was an InstanceListener interface. I create a simple Main class, that implements that and lists the instances.
So running this just adds a listener to the Hazelcast instance. According to the documentation Hazelcast allows for the following (and lots more):
# Distributed java.util.{Queue, Set, List, Map}
# Querying distributed data
I created a couple Main classes to run these separately, so that I could see if they are usable across different JVM executions.
So within minutes... I have a distributed cache across 4 applications, that I can monitor, control, query... (and btw. Hazelcast allows you to add indexes to the caches, same as a database to optimize queries).
If I was to place these 4 applications on 4 different machines, they will by default cluster (multicast for discovery) and have built in failover, monitoring and even persistence if required.
Coming from an environment where we have dozens of servers all caching data, this has got to be one of the most exciting open source products I have come across. Now I just need to convince the powers that be to prototype this and this may be the first open source project I actually try get involved in. The possibilities I am seeing for this type of functionality and then integrating it with the Spring Framework may actually make my brain explode.
"Hazelcast is pure Java. JVMs that are running Hazelcast will dynamically cluster. Although by default Hazelcast will use multicast for discovery, it can also be configured to only use TCP/IP for environments where multicast is not available or preferred. Communication among cluster members is always TCP/IP with Java NIO beauty. Default configuration comes with 1 backup so if one node fails, no data will be lost. It is as simple as using java.util.{Queue, Set, List, Map}. Just add the hazelcast.jar into your classpath and start coding."
I was instantly intrigued. So it sounds simple enough...Open IDE...jump in... being a maven fan, I figure, why download and manually "install" when you can just use maven, so I search around a little and add the following to a pom.
Edit: 1.8.4 is now outdated check http://www.hazelcast.com/downloads.jsp for the latest.
From the online documentation, I saw there was an InstanceListener interface. I create a simple Main class, that implements that and lists the instances.
So running this just adds a listener to the Hazelcast instance. According to the documentation Hazelcast allows for the following (and lots more):
# Distributed java.util.{Queue, Set, List, Map}
# Querying distributed data
I created a couple Main classes to run these separately, so that I could see if they are usable across different JVM executions.
So within minutes... I have a distributed cache across 4 applications, that I can monitor, control, query... (and btw. Hazelcast allows you to add indexes to the caches, same as a database to optimize queries).
If I was to place these 4 applications on 4 different machines, they will by default cluster (multicast for discovery) and have built in failover, monitoring and even persistence if required.
Coming from an environment where we have dozens of servers all caching data, this has got to be one of the most exciting open source products I have come across. Now I just need to convince the powers that be to prototype this and this may be the first open source project I actually try get involved in. The possibilities I am seeing for this type of functionality and then integrating it with the Spring Framework may actually make my brain explode.
Subscribe to:
Posts (Atom)
-
 I have been messing around with AWS on little side projects and experiments for about the last year. I did find it quite a daunting experien...
I have been messing around with AWS on little side projects and experiments for about the last year. I did find it quite a daunting experien... -
I make no claim to be a "computer scientist" or a software "engineer", those titles alone can spark some debate, I regar...